Testing
The Next Generation of Visual Testing AI Assistant


At LogicFlow, we assist our clients with the increase of productivity in their software development cycle. Specifically, in the field of regression tests, our Visual Testing AI assistant will learn the distinction between relevant and irrelevant changes. This frees up valuable time and motivation for skilful engineers to create interesting new features for the end-users.
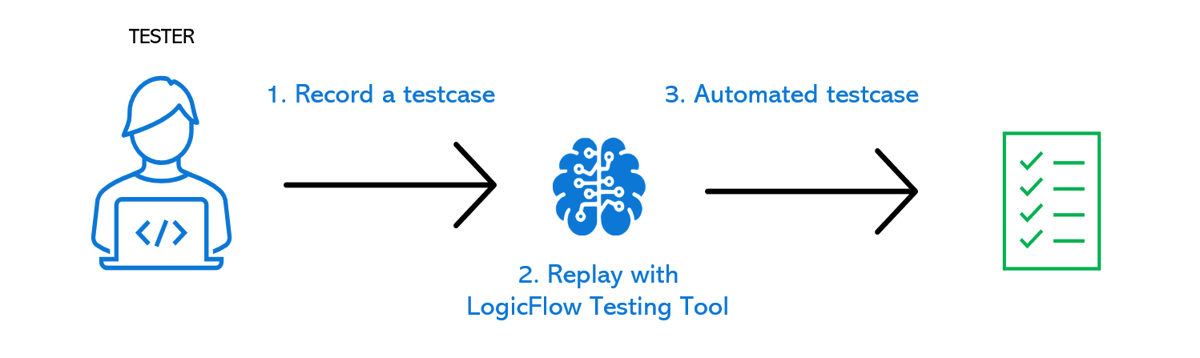
With the recording and replay options of the testing tool, the test engineer records a reference run through the web application under test. Then, when the engineer wants to test how a change has impacted the web application, the testing tool will automatically re-play the test and compare the new run to the reference run.
The AI backend of the tool first matches the DOM elements displayed on the screenshot of the reference run to the corresponding elements on the run to be compared. Once the matches have been established - the elements are checked for differences and classified as either irrelevant changes or relevant changes, which means whether the changes should be brought up to the attention of the engineer or not.
For this classification AI to be useful, the following criteria are considered:
Additionally, the GUI, which is instrumenting the tests and interacts with the AI should be intuitive and easy to use. In this, posts we will focus primarily on requirements for AI.
Let’s expand on the 3rd and 4th criteria on the list. How can the AI be designed in such a way that it is accurate enough to be useful in testing automation? What data should be used to train the AI? Imagine the following example:
Should this difference be classed as relevant or as irrelevant? It depends on the context.
For the first example, the difference could stem from a display of a “last login” date or be the result of selecting the 20th day in a calendar. In these cases, the difference should most likely be classed as irrelevant because the test might just have been run a month after the reference run. It could, however, be the due date of a bill as read from a database, and a new feature has corrupted the date in transit. In that case, the difference should be brought to the attention of the test engineer and flagged as relevant.
One way of providing the required context would be to just supply the whole screenshot rather than snippets of individual DOM elements. Note that in classical programming approaches, it is not necessarily clear which property is the deciding factor whether a difference is relevant or not. For example, the positioning on the screen could be a factor, but it doesn't have to be. The whole point of the AI approach is to let the AI learn it through the input of the tester. This would, however, require an unrealistic amount of training examples and a huge machine learning model. A better way of supplying context would be to supplement the screen snapshots of the DOM elements with numerical metadata, which would for example provide additional information about the positioning of the DOM element.
More crucially, the model learns from the tester. As the name suggests, the AI Assistant will not replace the testers but will be their assistant. Thus, the tester can concentrate on more interesting tasks such as coming up with novel ways of testing the limits of the application. Context isn’t even necessarily limited to anything, which can be observed with a “perfect” capability of analyzing information from the recorded test runs. It could be a difference in a test acceptance policy between different customers.
This would be somewhat similar to members of an orchestra. Even though they will know to play a piece based on the notes, they will need to get acquainted with the slight preferences of a specific conductor. No serious orchestra will practice with a range of different conductors in the leadup of a single concert. Because the inputs of each conductor might be contradictory, lead to ambiguity and confusion among the orchestra members. Similarly, one has to be very careful not to mix labelling input from different contexts into a single training set so as not to introduce ambiguity and inconsistent labelling, even if it would mean that the training set is bigger.
On the other, a conductor would not take upon the job of training the orchestra members from scratch and expects the big portion of the orchestra members’ skillset to be pre-trained.
Analogously, relying solely on training by the test engineers would demand a lot of manual labelling effort, which would violate the fourth requirement (“it must require minimal input for training and other user interaction, as the time savings should be overwhelming”). To provide a baseline judgement of the overwhelming majority of obvious cases, the visual testing AI assistant will therefore be delivered pre-trained.
As the testers and test engineers refine the training for their application, those modifications will be used by the AI to adapt to the requirements of the specific customer.

Reach the automation level you are aiming for
Leverage no-code and write custom code where needed
Visualize your end-user experience all in one place
Make your deployment decisions easy

